

Alibaba’s newly launched Wan2.7-Image aims to transform the image generation and editing landscape by empowering creators to produce high-fidelity, personalised visuals with professional-grade precision. Also unveiled is Wan2.7-Image-Pro, which offers more stable image composition, a sharper and more precise understanding of prompts with high-definition 4K output.
Historically, AI-generated images have been plagued by a generic look and unpredictable colour results. Wan2.7-Image transcends these earlier shortcomings, providing creators with the tools needed to produce professional, tailored work without the usual frustration of AI trial-and-error.
Wan2.7-Image enables creators to generate images from text, while boosting their productivity by processing multiple images at once. It brings refinement to visuals through simple, instruction-based editing. In anonymised human preference tests, the model delivers exceptional visual fidelity, precise text rendering, and a deep understanding of complex visual concepts.
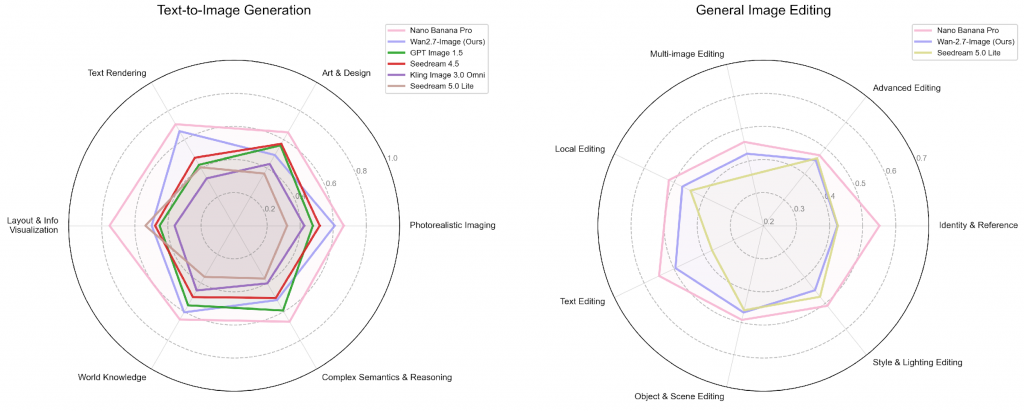
Wan2.7-Image replaces the generic, standardised look of typical AI with deep personalization. This enables users to fine-tune specific features like bone structure and eye shape to create truly unique, lifelike characters tailored for every project. It also ends the guesswork of AI colour rendering with a new “colour palette” feature: by simply entering specific colour codes and proportions into a prompt, creators can replicate complex artistic styles or lock-in exact brand colours, ensuring every image perfectly matches their vision or corporate guidelines.

Wan2.7-Image also marks a significant breakthrough in text rendering, which is a persistent challenge for AI. Wan2.7-Image facilitates text inputs of up to 3,000 tokens. Offering support for 12 languages, the model generates print-quality academic text, complex formulas and tables. With the ability to use as many as nine reference images and generate up to 12 images at once, the model makes it simple to create cohesive storyboards, architectural renderings and e-commerce campaigns.
The new model empowers creators further with its intuitive “click-to-edit” interface that ensures precision in every detail. By selecting specific areas of an image, users can seamlessly add, move, or align elements with pixel-level accuracy, effectively eliminating the unpredictability often associated with AI-generated content.
This precision is driven by a state-of-the-art framework that bridges the gap between language and visuals. By training on vast, diverse datasets, Wan2.7-Image moves beyond simple pixel-matching to achieve a deep, semantic understanding of lighting, composition, and layout. This enables the model to interpret user intent with much higher levels of accuracy.